简易HttpServer
1.说明
该httpserver主要是对Tinyhttpd的中文注释以及一些bug的修复以及几个新功能的添加。
Code:
gitOSC开源中国
2.HTTP
GET
根据HTTP规范,GET用于信息获取,而且应该是安全的和幂等的 。
HTTP请求:
<request line>
<headers>
<blank line>
<request-body>
在HTTP请求中,第一行必须是一个请求行(request line),用来说明请求类型、要访问的资源以及使用的HTTP版本。紧接着是一个首部(header)小节,用来说明服务器要使用的附加信息。在首部之后是一个空行,再此之后可以添加任意的其他数据[称之为主体(body)]。
GET /books/?sex=man&name=Professional HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Connection: Keep-Alive
POST
根据HTTP规范,POST表示可能修改变服务器上的资源的请求 。
POST / HTTP/1.1
Host: www.wrox.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 40
Connection: Keep-Alive
(----此处空一行----)
name=Professional%20Ajax&publisher=Wiley
3.HTTP Response
响应格式
<status line>
<headers>
<blank line>
[<response-body>]
响应实例:
HTTP/1.1 200 OK
Date: Sat, 31 Dec 2005 23:59:59 GMT
Content-Type: text/html;charset=ISO-8859-1
Content-Length: 122
<html>
<head>
<title>Wrox Homepage</title>
</head>
<body>
<!-- body goes here -->
</body>
</html>
最常用的状态码
- 200 (OK): 找到了该资源,并且一切正常。
- 304 (NOT MODIFIED): 该资源在上次请求之后没有任何修改。这通常用于浏览器的缓存机制。
- 401 (UNAUTHORIZED): 客户端无权访问该资源。这通常会使得浏览器要求用户输入用户名和密码,以登录到服务器。
- 403 (FORBIDDEN): 客户端未能获得授权。这通常是在401之后输入了不正确的用户名或密码。
- 404 (NOT FOUND): 在指定的位置不存在所申请的资源。
4.主要函数
//处理从套接字上监听到的一个HTTP请求
void *accept_request(void*);
//返回给客户端这是个错误请求
void bad_request(int);
//读取服务器上某个文件写到套接字
void cat(int, FILE *);
//主要处理发生在执行cgi程序时出现的错误
void cannot_execute(int);
//把错误信息写到perror并退出
void error_die(const char *);
//运行cgi程序
void execute_cgi(int, const char *, const char *, const char *);
//读取套接字的一行
int get_line(int, char *, int);
//把HTTP响应的头部写到套接字
void headers(int, const char *);
//主要处理找不到请求的文件时的情况
void not_found(int);
//调用cat服务把服务器文件返回给浏览器
void serve_file(int, const char *);
//初始化httpd服务,包括建立套接字,绑定端口,进行监听等等
int startup(u_short *);
//返回给浏览器表明收到的HTTP请求所用的method不被支持
void unimplemented(int);
//写出日志内容到日志文件
void write_log(char* log_str);
5.思路:
- 服务器启动,在指定端口绑定 httpd 服务。
- 收到一个 HTTP 请求时(其实就是 listen 的端口 accpet 的时候),派生一个线程运行 accept_request 函数。
- 取出 HTTP 请求中的 method (GET 或 POST) 和 url,。对于 GET 方法,如果有携带参数,则 query_string 指针指向 url 中 ? 后面的 GET 参数。
- 格式化 url 到 path 数组,表示浏览器请求的服务器文件路径,服务器文件是在 htdocs 文件夹下。当 url 以 / 结尾,或 url 是个目录,则默认在 path 中加上 index.html,表示访问主页。
- 如果文件路径合法,对于无参数的 GET 请求,直接输出服务器文件到浏览器,即用 HTTP 格式写到套接字上,跳到(10)。其他情况(带参数 GET,POST 方式,url 为可执行文件),则调用 excute_cgi 函数执行 cgi 脚本。
- 读取整个 HTTP 请求并丢弃,如果是 POST 则找出 Content-Length. 把 HTTP 200 状态码写到套接字。
- 建立两个管道,cgi_input 和 cgi_output, 并 fork 一个进程。
- 在子进程中,把 STDOUT 重定向到 cgi_outputt 的写入端,把 STDIN 重定向到 cgi_input 的读取端,关闭 cgi_input 的写入端 和 cgi_output 的读取端,设置 request_method 的环境变量,GET 的话设置 query_string 的环境变量,POST 的话设置 content_length 的环境变量,这些环境变量都是为了给 cgi 脚本调用,接着用 execl 运行 cgi 程序。
- 在父进程中,关闭 cgi_input 的读取端 和 cgi_output 的写入端,如果 POST 的话,把 POST 数据写入 cgi_input,已被重定向到 STDIN,读取 cgi_output 的管道输出到客户端,该管道输入是 STDOUT。接着关闭所有管道,等待子进程结束。这一部分比较乱,见下图说明:
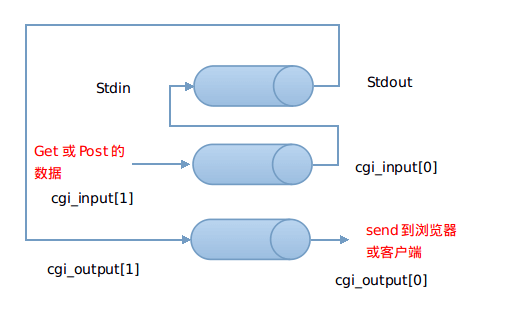
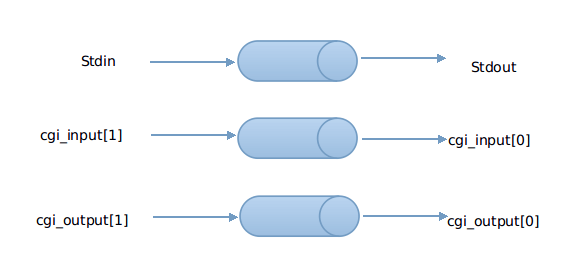
- 关闭与浏览器的连接,完成了一次 HTTP 请求与回应,因为 HTTP 是无连接的。
6.cgi支持
cgi文件通过execl调用,然后输入输出如上图所示。子进程调用,然后通过管道连接和主线程的输入与输出,同时重定向管道的输入和输出 cgi与主进程的数据交换使用的方法是设置临时环境变量
//在server上:
/*设置 request_method 的环境变量*/
sprintf(meth_env, "REQUEST_METHOD=%s", method);
putenv(meth_env);
//在cgi上
data=getenv("QUERY_STRING");
respondNum=sscanf(data,"a=%d&b=%d",&a,&b);
7.日志记录
一般的日志主要包括:访问者的ip,请求的网址,get or post。
访问者ip是在接收到客户端的请求里。client_name是sockaddr_in
struct sockaddr_in {
short int sin_family; /* Address family */
unsigned short int sin_port; /* Port number */
struct in_addr sin_addr; /* Internet address */
unsigned char sin_zero[8]; /* Same size as struct sockaddr */
};
而请求则是client通过socekt send发送的信息。在处理请求的时候保存下来即可 我是在每个client线程接收到get post请求解析出之后,保存到buf里,最后在写入到log文件里。
8.遇到的问题
pthread_create传递参数
为了能够给单独的线程传递日志内容,在create的时候要传递结构体参数,
typedef struct
{
int client;
char logContent[1024<<2];
}clientStruct;
clientStruct newClient;
newClient.client=client_sock;
strcat(newClient.logContent,buf);
/*派生新线程用 accept_request 函数处理新请求*/
/* accept_request(client_sock); */
if (pthread_create(&newthread , NULL, accept_request, (void*)&newClient) != 0)
perror("pthread_create");
client与server交互
client一直和server没法交互信息,倒是浏览器很快就成功了。 尝试了好久,才明白必须要伪造http header,因为在server上,是按步骤接收信息,如果只是发送一两行来测试,server根本没有处理完,仍在等待信息发过去。 之前一直没有加printf来调试,在这里就有了很大的作用,可以清除的看到server停在了哪部分之前。 接收server发过来的信息的时候,直接从网上搜到了一个recv_msg的方法,传进去sockfd就可以了。
buf设置过小
在server和client设置的接收和发送的buf都应该足够大,client一开始用buf累计的时候,出现过只显示了一部分的情况。直到考虑到可能是buf设置的问题。。。 针对这个问题,一个方法是增大buf,比如从1024增大到1024*1024,或者增加检测机制,当buf就要满时,写出到屏幕或者文件,然后从头开始接收。
判断服务器文件or目录
stat 结构定义于:/usr/include/sys/stat.h 文件中
函数可以得到文件的信息,将其保存在buf结构中,buf的地址以参数形式传递给stat。
Reference:
HTTP POST GET 本质区别详解 http://blog.csdn.net/gideal_wang/article/details/4316691 Linux C编程--进程间通信(IPC)4--管道详解 http://blog.csdn.net/dlutbrucezhang/article/details/8636706 Getting Started with CGI Programming in C https://www.cs.tut.fi/~jkorpela/forms/cgic.html sockaddr与sockaddr_in结构体简介 http://blog.csdn.net/lihengzk/article/details/1415312 pthread_create传递参数 http://blog.csdn.net/liangxanhai/article/details/7767430 stat百度百科 http://baike.baidu.com/view/568600.htm#2
Comments